

Built-in prompt schemas for media intelligence workflows
Prompting a model to “analyze this video” is easy. Designing a production schema for video AI is harder. The schema must describe the media clearly enough for users, remain stable enough for software, and preserve enough source context for review, search, automation, and VideoRAG.
VectorMethods handles this through schema-aware video metadata extraction in VideoVector. Teams can define fields, nested objects, arrays, enums, required paths, and asset-level outputs for their own workflows. This turns LLM-based video extraction from a free-form response into a structured data contract.
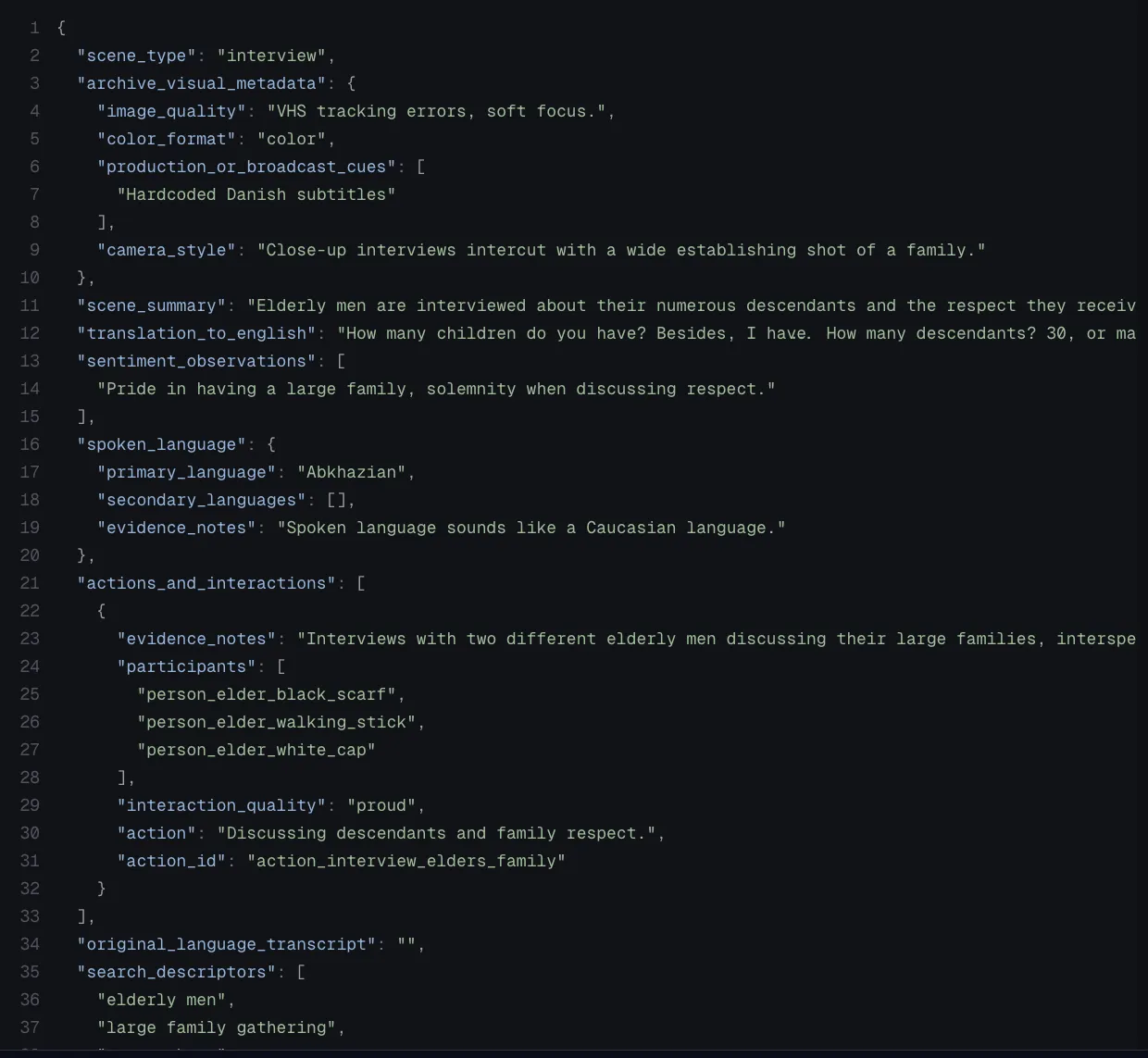
Nested JSON output from archive media extraction
A strong schema separates segment-level and asset-level meaning. Segment-level fields describe what happened at a specific timestamp: scene type, action, visible entity, spoken language, safety condition, visual state, or event context. Asset-level fields summarize the full media object: catalog category, title, descriptors, topics, risk state, recommendation features, or archive classification.
This matters for video metadata extraction. If an application needs video scene extraction or video segment analysis, the segment schema must preserve time anchors. If a downstream catalog needs discovery fields, the asset schema must produce stable descriptors. If a search system needs semantic indexing, selected fields should become metadata text while exact fields remain available for filters.
Good schemas are domain-specific. A lecture schema might include learning objectives, formulas, board content, prerequisite concepts, and learner actions. A sports schema might include play state, highlight candidates, athletes, camera view, and editorial tags. An archive schema might include people, places, translation, content classification, catalog tags, and natural-language search terms.
Developers can operationalize these schemas through the SDK. A product workflow can run the same extraction schema repeatedly, retrieve typed outputs, and route them to a database, review UI, search index, analytics pipeline, or downstream automation service.
Schema design also improves search. Once fields are stable, teams can combine semantic retrieval with structured constraints through multimodal media search. Vector search for video scenes and events handles recall, while field filters and SQL search handle precision.
The practical pattern is to start with the workflow. What will the consuming system do with the result? Render it? Filter on it? Rank with it? Export it? Use it for VideoRAG? The answer should shape the schema. VideoVector gives teams the extraction and validation layer needed to make those schemas useful across media types and production systems.